

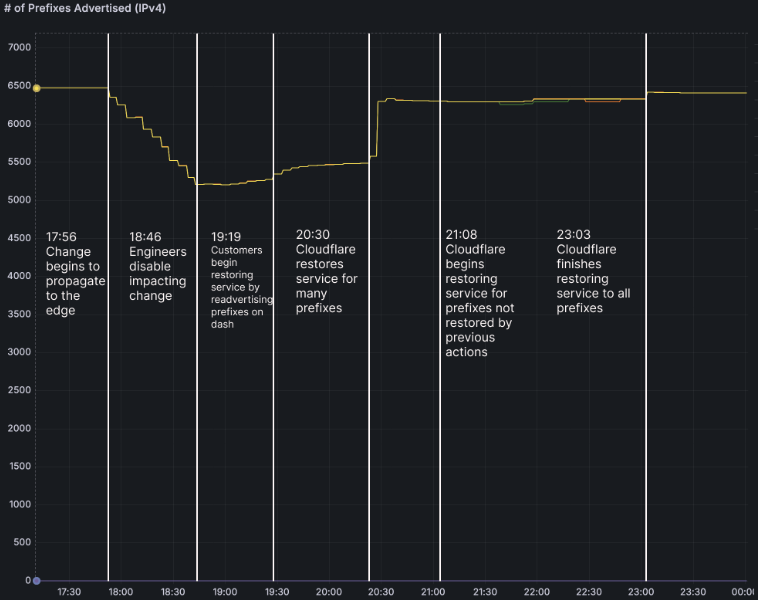
Uma instabilidade registrada em 20 de fevereiro de 2026 na rede da Cloudflare dificultou o acesso a diversos serviços online ao redor do mundo. A empresa, responsável por fornecer infraestrutura para milhões de sites, confirmou que o problema ocorreu por causa do anúncio incorreto de rotas de internet utilizadas por alguns clientes.
Mesmo assim, a equipe técnica resolveu o incidente rapidamente. Ainda assim, o episódio reacendeu discussões sobre o nível de dependência da internet moderna em grandes provedores de rede.
- Leia também: Falha no PayPal deixou dados sensíveis expostos durante seis meses
- Leia também: É possível construir data centers de IA no espaço? Entenda os desafios
- Leia também: WhatsApp começa a testar agendamento de mensagens no aplicativo
Como o problema começou
De acordo com informações divulgadas pela própria Cloudflare, parte dos endereços IP utilizados por clientes deixou de ser propagada corretamente na internet. Como resultado, outros provedores de rede não conseguiam identificar o caminho até esses serviços.
Em outras palavras, determinados sistemas praticamente desapareceram do mapa da internet por um período.
Esse tipo de situação está ligado ao funcionamento do Border Gateway Protocol. Esse protocolo informa aos provedores quais caminhos devem ser usados para alcançar cada rede. Portanto, quando algo falha nesse processo, serviços online podem se tornar inacessíveis.
Impacto percebido pelos usuários
Durante a instabilidade, muitos usuários relataram dificuldades para acessar sites e aplicações que utilizam a infraestrutura da empresa.
Como a Cloudflare atua entre servidores e visitantes — oferecendo proteção, cache e otimização — qualquer alteração em sua rede pode afetar rapidamente uma grande quantidade de serviços digitais. Além disso, plataformas corporativas e aplicações populares também podem sofrer impacto.
Por esse motivo, até interrupções curtas acabam sendo percebidas por usuários em diferentes regiões.
Os clientes BYOIP afetados inicialmente experimentaram um comportamento chamado BGP Path Hunting . Nesse estado, as conexões dos usuários finais percorrem as redes tentando encontrar uma rota para o IP de destino. Esse comportamento persistirá até que a conexão aberta expire e falhe. Até que o prefixo seja anunciado em algum lugar, os clientes continuarão a observar esse modo de falha. Esse cenário de loop infinito afetou qualquer produto que utilize BYOIP para anúncios na Internet. Além disso, os visitantes do site one.one.one.one, o site do resolvedor DNS recursivo da Cloudflare, se depararam com erros HTTP 403 e uma mensagem de erro “Edge IP Restricted”. A resolução de DNS pelo resolvedor público 1.1.1.1, incluindo DNS sobre HTTPS, não foi afetada. Uma descrição completa dos serviços afetados encontra-se abaixo.
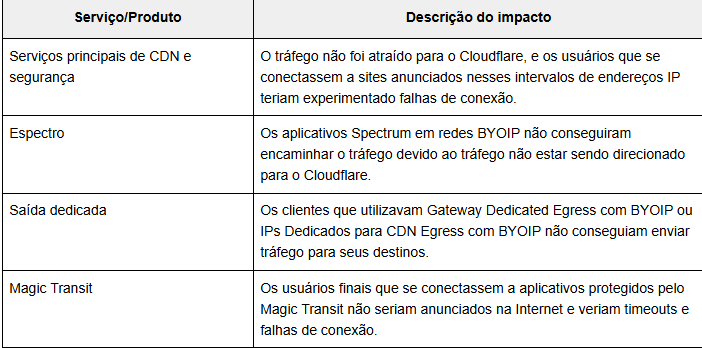
Havia também um grupo de clientes que não conseguiu restabelecer o serviço ao ativar ou desativar os prefixos no painel da Cloudflare. À medida que os engenheiros começaram a reanunciar os prefixos para restabelecer o serviço para esses clientes, eles podem ter experimentado aumento de latência e falhas, apesar de seus endereços IP estarem sendo anunciados. Isso ocorreu porque as configurações de endereçamento de alguns usuários foram removidas dos servidores de borda devido a um problema em nosso próprio software, e o estado teve que ser propagado de volta para a borda.
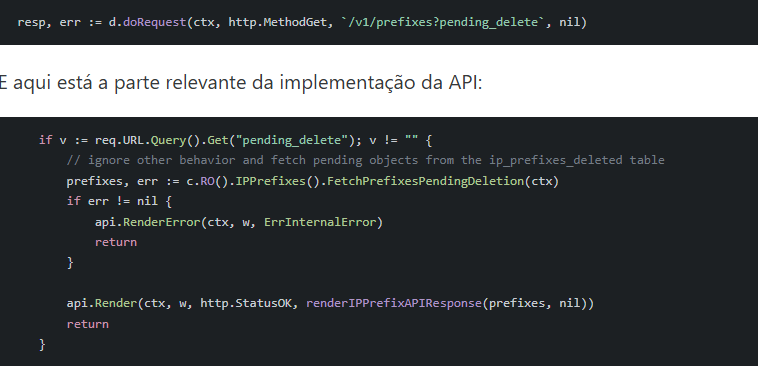
Vamos analisar exatamente o que falhou em nosso sistema de endereçamento, mas para isso precisamos fazer uma breve introdução à API de Endereçamento, que é a fonte de verdade subjacente aos endereços IP dos clientes na Cloudflare.
O que causou a falha
As análises iniciais indicam que uma alteração relacionada ao gerenciamento de prefixos de IP removeu anúncios que deveriam permanecer ativos.
Sem essas rotas disponíveis, parte do tráfego da internet não encontrava o caminho correto até os sistemas protegidos ou hospedados na Cloudflare.
A empresa explicou que o evento não ocorreu por causa de um ataque cibernético. Em vez disso, o problema surgiu durante uma mudança operacional na rede.
Melhor arbitrar ações de saque em grande escala
Aprimoraremos nosso monitoramento para detectar quando as alterações estiverem ocorrendo muito rapidamente ou de forma muito abrangente, como a retirada ou exclusão repentina de prefixos BGP, e desativaremos a implantação de snapshots quando isso acontecer. Isso funcionará como um mecanismo de segurança para impedir que qualquer processo descontrolado que esteja manipulando o banco de dados tenha um impacto generalizado, como vimos neste incidente.
Também estamos trabalhando para monitorar diretamente se os serviços executados por nossos clientes estão funcionando corretamente, e esses sinais podem ser usados para acionar o disjuntor e impedir a aplicação de alterações potencialmente perigosas até que tenhamos tempo para investigar. Esse trabalho está alinhado com a primeira frente de ação do Código Laranja, que envolve a implementação segura de alterações.
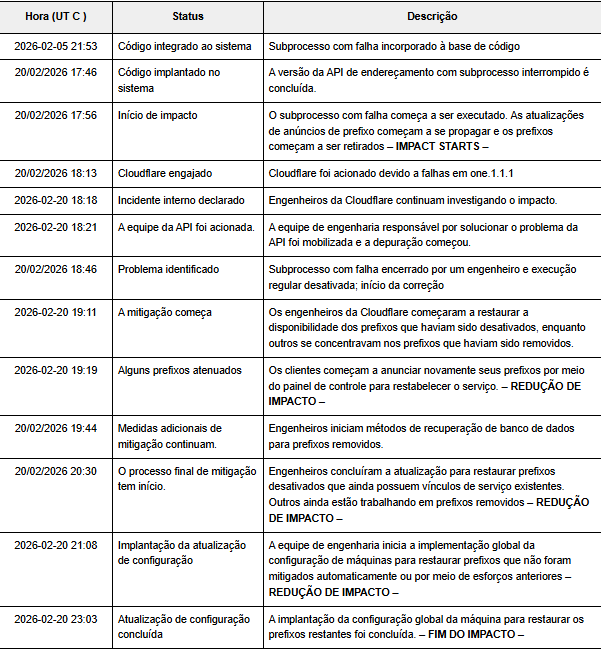
A seguir, apresentamos o cronograma dos eventos, incluindo a implementação da alteração e as etapas de correção:
Recuperação do serviço
Assim que os engenheiros identificaram a origem da falha, a equipe restaurou os anúncios de rota afetados. Em seguida, o tráfego começou a voltar ao normal gradualmente.
Além disso, os sistemas de monitoramento ajudaram a detectar rapidamente o comportamento anormal na rede.
Lições deixadas pelo incidente
Casos como esse mostram como a infraestrutura da internet funciona de forma altamente interligada. Atualmente, grandes provedores concentram serviços essenciais que sustentam desde pequenos blogs até plataformas globais.
Por isso, quando um componente dessa cadeia apresenta falhas, o impacto pode se espalhar rapidamente.
Diante disso, empresas do setor investem continuamente em redundância, monitoramento e revisão de processos para reduzir a chance de novos incidentes.
Qual a relação desse incidente com o Código Laranja: Falhe Pequeno?
A alteração que estávamos implementando quando esse incidente ocorreu faz parte da iniciativa Code Orange: Fail Small, que visa aprimorar a resiliência do código e da configuração na Cloudflare. Em resumo, a iniciativa Code Orange: Fail Small pode ser dividida em três partes principais:
- Exigir implementações controladas para qualquer alteração de configuração que seja propagada para a rede, assim como fazemos hoje para lançamentos de software binário.
- Alterar nossos procedimentos internos de “emergência” e eliminar quaisquer dependências circulares para que nós, e nossos clientes, possam agir rapidamente e acessar todos os sistemas sem problemas durante um incidente.
- Analisar, aprimorar e testar os modos de falha de todos os sistemas que lidam com tráfego de rede para garantir que apresentem um comportamento bem definido em todas as condições, incluindo estados de erro inesperados.
A alteração que tentamos implementar se enquadra na primeira categoria. Ao migrar alterações manuais e arriscadas para atualizações de configuração seguras e automatizadas, implementadas de forma controlada por indicadores de integridade, buscamos melhorar a confiabilidade do serviço.






